 17认证网
17认证网由 OceanBase 团队撰写的系统论文《OceanBase Mercury: Building a Distributed Real-time Analytical Processing Database System》被数据库领域国际顶级会议 IEEE International Conference on Data Engineering(ICDE 2026)正式录用。
ICDE 是由 IEEE 主办的年度国际会议,与 SIGMOD、VLDB 并称数据库领域三大顶级会议,也是中国计算机学会 CCF 推荐的 A 类国际会议,在学术界和工业界享有极高声誉。本论文系统性阐述了 OceanBase Mercury 在“一套系统同时承载事务处理与实时分析”这一长期难题上的技术突破,提出自适应混合列式存储、物化视图增量刷新、多态向量化执行引擎三大核心创新,为新一代实时分析数据库的设计提供了完整参考。
OceanBase Mercury(即 OceanBase 4.3.3)是 OceanBase 自研的分布式实时分析型数据库系统,专为 PB 级数据规模设计,在保留完整 OLTP 事务能力的同时,实现了接近实时的大规模分析查询。
在TPC-H、TPC-DS、ClickBench 等主流基准测试中,OceanBase Mercury全面超越 StarRocks 和 ClickHouse 等专用 OLAP引擎,查询延迟最高降低 3.1 倍,并已在 OceanBase 内部大数据平台和公有云产品中完成规模化落地。
问题背景
大数据时代,企业对数据库系统的要求越来越苛刻:既要能处理海量数据,又要同时支持稳定的事务处理和近乎实时的分析能力。业务场景中,数据刚刚写入就需要被查询分析,延迟要求往往在毫秒级。
然而现有方案均存在明显短板:
1.传统 OLAP 系统(如 ClickHouse、StarRocks)在相对静态的数据上表现出色,却无法很好地支持高频写入与实时可见;
2. 采用“OLTP + OLAP”多系统组合的方案,虽然覆盖了两种工作负载,却引入了大量数据冗余和复杂的跨系统同步开销,整体效率大打折扣;
3. 现有 HTAP 系统大多在列存集成上有所取舍:要么需要独立的分析基础设施,要么难以在保持事务能力的同时实现真正的列式分析性能。
核心矛盾在于:如何在一套统一系统中,既具备完整的事务处理能力、能够承载高频 DML 负载,又能实现 PB 级数据的高性能实时分析?
OceanBase Mercury 正是为破解这一挑战而生。它以 OceanBase 久经考验的分布式架构(已在生产环境支撑超 20PB、1500 节点集群、超 7 亿 tpmC 的事务处理能力)为基础,提出三项核心技术创新,构建出一套真正统一 TP/AP 能力的实时分析数据库系统。
核心技术
核心技术一:自适应混合列式存储
传统列存数据库为了获得分析性能,往往牺牲了 DML(数据增删改)能力——列存天然不友好于随机写入和单行更新。OceanBase Mercury 通过将行存与列存深度融合,彻底打破了这一限制。
设计核心:LSM-Tree 原生混合存储
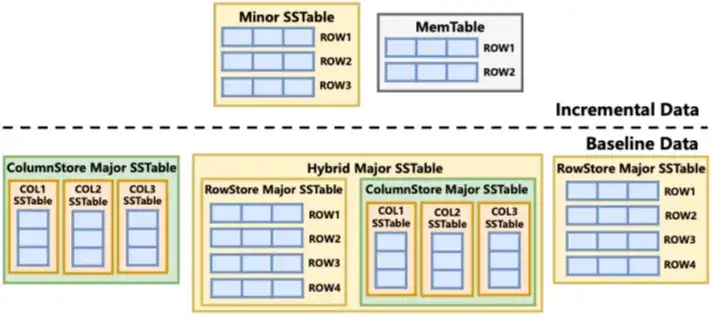
混合存储架构(列存基线 + 行存增量)
Mercury充分利用 OceanBase LSM-Tree 存储引擎的特性,将用户数据划分为两个层次:
1.基线数据(Baseline Data):经过每日压缩合并(Major Compaction)后,以列存格式存储。每一列独立存为一个 SSTable,并通过虚拟 SSTable 对上层透明呈现。列存基线充分发挥列式扫描的分析性能优势。
2. 增量数据(Incremental Data):所有新写入的数据(MemTable + minor SSTable)仍保留在行存中,保证完整的事务处理能力,所有 DML 操作与行存表完全一致,对用户完全透明。
查询时,引擎将列存基线数据与行存增量数据实时合并,数据新鲜度趋近于 0(即刚提交的事务立刻可查),同时不影响 OLTP 写入性能。在大规模生产环境中,增量数据仅占每日写入量的 1%–10%,大部分时间查询都能充分享受列存的性能红利。
三种存储模式灵活可选
用户可按业务负载类型灵活配置:纯行存、纯列存、或行列冗余模式(兼顾 OLTP和 OLAP)。列存表与行存表在使用体验上完全统一,支持所有 DDL、所有数据类型和二级索引。
列式编码与数据跳过索引
Mercury 针对列式存储设计了新的编码算法,包括多前缀编码、列间等值编码、列间子串编码,在提升压缩比的同时支持 SIMD 加速和无需解压的直接查询。以真实业务数据集为例,部分表的空间节省率从 66% 大幅提升至 87%。
同时,Mercury 引入数据跳过索引(Data Skipping Index),将预聚合sketch(最大值、最小值、求和、Null 计数)与 SSTable 多层索引结构对齐,实现从数据块到SSTable 粒度的多分辨率动态剪枝,显著加速过滤、聚合和优化器统计收集,且无需额外调参。
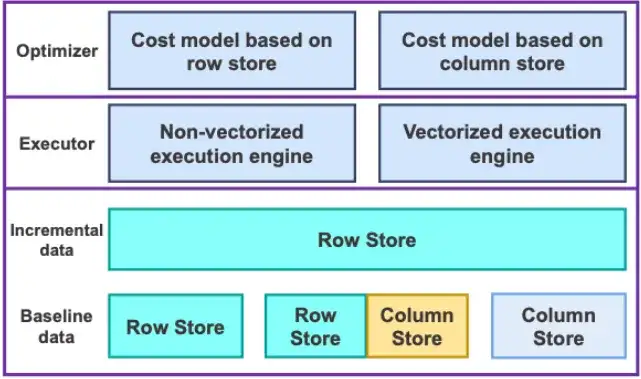
行存与列存在 SQL 引擎、存储引擎、事务引擎层的深度集成
物化视图(Materialized View)是加速分析查询的经典手段——预先计算并存储复杂查询结果,查询时直接读取,避免重复计算。而高频写入场景下如何低成本地维护物化视图,始终是工程难点。
Mercury提供两种刷新策略,覆盖不同场景:
全量刷新(Full Refresh)
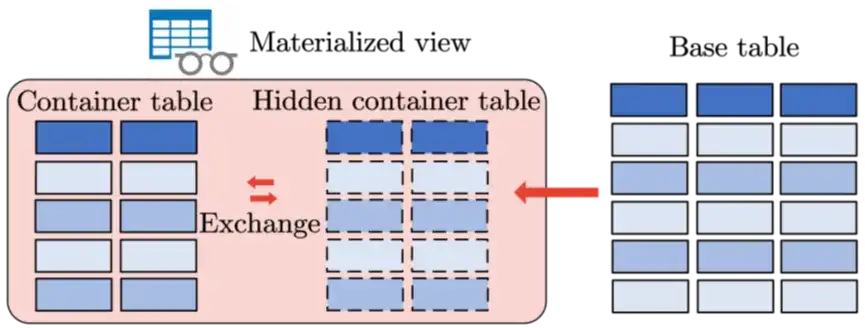
全量刷新
采用“异地刷新”方式:创建隐藏临时表,将完整数据集写入后再与原物化视图表进行原子切换,保证刷新过程不影响正常查询服务。全量刷新借助“直接加载(Direct Load)技术”,绕过 SQL 接口和事务处理层,直接以 SSTable 格式写入存储层,大幅提升导入效率。该方式尤其适合基表变化较大或数据量相对较小(< 10GB)的场景。
增量刷新(Incremental Refresh)
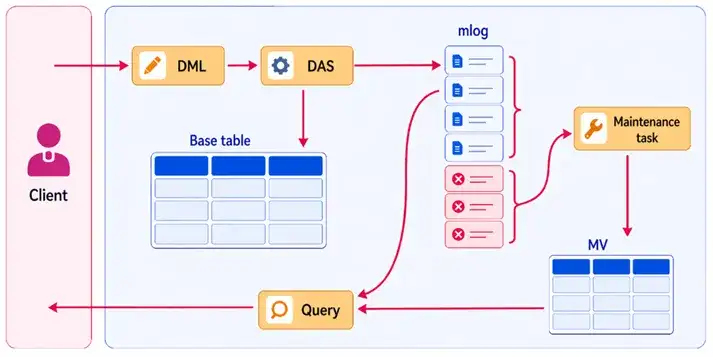
增量刷新整体框架(DAS 写入 mlog + 后台维护任务刷新 MV)
通过“物化视图日志(mlog)”记录基表每一行的增量变更(DML 类型、修改前后的值),后台维护任务定期将 mlog 中的增量更新应用到物化视图。增量刷新的代价远低于全量刷新,适合基表持续高频更新的场景。同样支持增量直接加载,将增量数据直接以 SSTable 格式写入,进一步提升刷新效率。
无论哪种刷新模式,Mercury 的“实时物化视图查询”都会同时读取 MV 表数据与 mlog 未刷新部分,实时合并返回,确保查询结果始终反映最新状态,数据新鲜度同样趋近于 0。
核心技术三:多态向量化执行引擎
向量化执行是提升分析查询吞吐量的关键技术:相比逐行处理的 Volcano 模型,向量化引擎每次处理一批数据,大幅减少函数调用开销,提高 CPU 缓存命中率,充分发挥 SIMD 指令潜力。
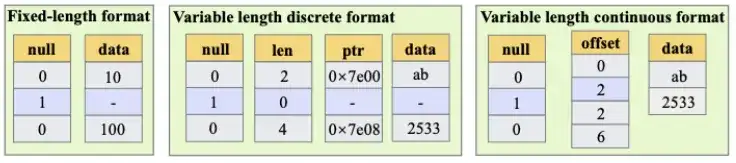
向量化引擎三种数据格式示意图
三种数据格式,适配不同计算场景
Mercury 在向量化引擎中设计了三种列式数据格式,以应对不同数据类型和计算模式:
1. 定长格式:仅存 Null 位图和连续数据,无冗余长度和指针信息,SIMD 友好,批量拷贝高效,适合整型、浮点等数值数据;
2. 变长离散格式:通过地址指针和长度描述,数据可不连续存放,适合短路计算和列编码数据投影(无需深拷贝),灵活性强;
3. 变长连续格式:数据在内存中连续存放,通过偏移数组描述,批量拷贝效率更高,主要用于列式物化场景。
算子与表达式全面重构
基于新的数据格式,Mercury 对 Sort、Hash Group By、Data Shuffle、聚合计算等核心算子进行了全面重新设计:
- 利用批量数据属性信息(Null 是否存在、是否需要过滤)跳过不必要的计算路径;
- Sort 算子实现排序键与非排序键分离物化,配合保序编码,减少数据缓存缺失;
- Hash Group By 采用更紧凑的 HashBucket 结构,低基数 Group Key 改用数组连续存储;
- Hash Join 将多个定长 Join Key 编码为单列,将 Join Key 数据直接放入Bucket,减少多列访问的缓存缺失;
- 存储层全面支持向量化格式,通过 SIMD 加速投影、谓词下推、聚合下推和Group By 下推。
性能成果
Mercury 在单机和三节点集群两种环境下,使用 TPC-H(700GB/1TB)、TPC-DS(700GB/1TB)和 ClickBench 等基准测试进行了全面评估,硬件配置为 128 核 Intel Xeon Platinum 8369B、1TB DRAM、44TB HDD。
向量化引擎提升效果
与关闭向量化引擎相比,开启后整体查询延迟在冷查场景下降低 6%–33%,热查场景下降低 18%–28%。在 ClickBench 单表大查询场景下,集群模式冷查延迟降低 33%,热查降低 27%。典型案例:TPC-DS Q23 查询从 138.99 秒降至 77.17 秒,提升幅度达 44.5%。列存模式相较行存模式,在 ClickBench、TPC-H 100G、TPC-DS 100G 上分别实现 1.7×–1.8× 加速。
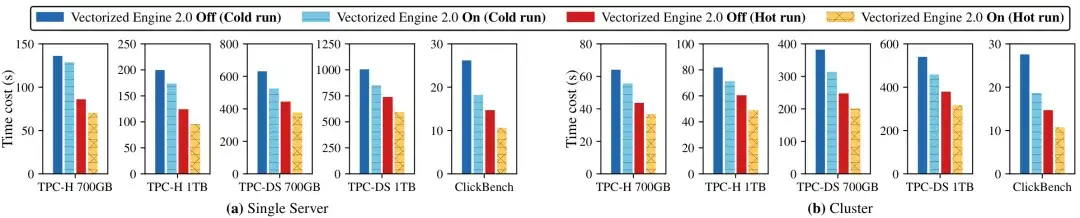
开启/关闭向量化引擎的总查询延迟对比
对比 StarRocks & ClickHouse
TPC-H基准测试:在 TPC-H 700GB 场景下,Mercury 较 StarRocks 单机查询延迟降低 23.7%,集群模式延迟降低33.8%;在 TPC-H 1TB 场景下,单机延迟降低 46%,集群延迟降低 19%。复杂查询优势尤为显著,Mercury 仅耗时6.07 秒,而 StarRocks 需 24.3秒,ClickHouse 高达 163.0 秒,Mercury相较 ClickHouse 实现了约“27×”加速。此外,ClickHouse由于不支持部分 TPC-H 查询且单查询处理时间超过 1 小时,无法完整参与TPC-H 基准对比。
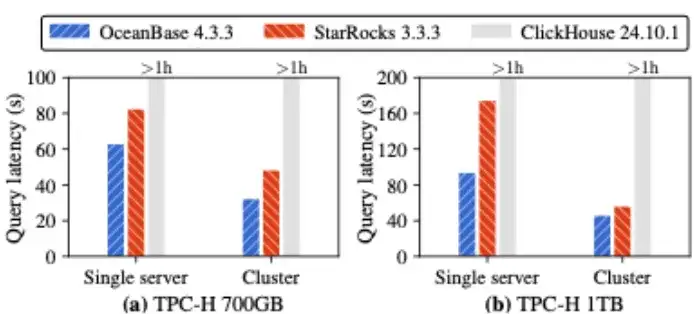
OceanBase vs. StarRocks & ClickHouse TPC-H查询延迟
ClickBench 基准测试:在仅 16 核 CPU + 32GB 内存的资源受限环境下,Mercury 的冷查延迟较 StarRocks 降低 68%,较 ClickHouse 降低 57%;热查场景下分别降低 35% 和 23%。
单点表现同样亮眼——ClickBench Q24 查询中,Mercury仅需 4.4 秒完成,而 StarRocks 耗时 46.5秒、ClickHouse 耗时 36.2 秒,Mercury相较 StarRocks 实现约“10×”加速。这说明 Mercury 不仅在高规格服务器上表现强劲,在资源受限的中小规模部署中同样具备显著优势,更契合真实云环境下的多租户场景。
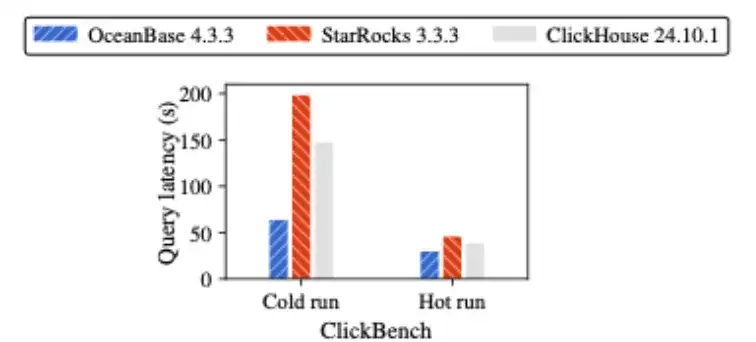
OceanBase vs. StarRocks & ClickHouse ClickBench查询延迟
写密集场景对比 Doris
在模拟真实业务的写密集场景下(写比例 0.0–0.2),OceanBase 平均响应时间约853ms,Doris 约 4327ms,OceanBase 综合性能约为 Doris 的 5 倍。
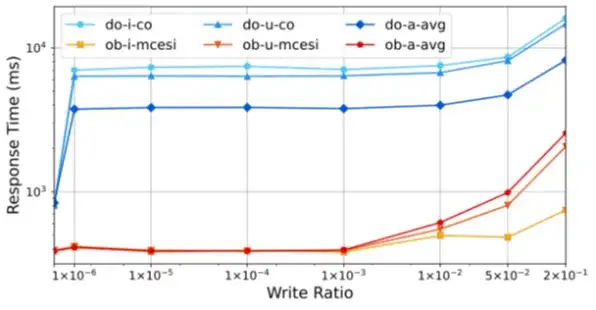
OceanBase vs. Doris 写密集场景平均响应时间对比
小结与展望
OceanBase Mercury 通过三项核心创新——“混合行列存储”“物化视图增量刷新”“多态向量化执行引擎”——在一套统一系统内实现了 PB 级数据的事务处理与近实时分析的深度融合。
在主流基准测试和真实业务场景中,Mercury 全面超越了 StarRocks、ClickHouse 等专用 OLAP 引擎,最高实现 3.1 倍的查询延迟提升,并已在生产环境中规模化落地。
基于实际部署经验,团队也提炼出若干工程洞见:多存储模型并存对优化器代价模型提出了更高要求;增量数据堆积与压缩合并之间需要更精细的监控与调度;物化视图刷新应更充分利用并行 DML 和批量加载技术;ARM 芯片在成本效益上具有更大潜力,计算引擎在该架构下仍有深度优化空间。
未来,OceanBase 团队将持续探索编码感知计算(直接在编码数据上进行聚合/排序/Join 运算)、ARM 环境专项优化、以及动态负载自适应压缩调度等方向,推动 HTAP 数据库从「可用」走向「极致高效」。
转自:OceanBase数据库
版权申明:内容来源网络,版权归原创者所有,如有侵权请联系删除
想了解更多行业资讯
扫码关注👇

了解更多考试相关
扫码添加上智启元官方客服微信👇
















